Harmonia: an Open-source Federated Learning Framework
Federated learning is a machine learning method that enables multiple parties (e.g., mobile devices or organization) to collaboratively train a model orchestrated by a trustable central server while keeping data locally. It has gained a lot of attention recently due to the increasing awareness of data privacy.
In Taiwan AI Labs, we started an open source project which aims at developing systems/infrastructures and libraries to ease the adoption of federated learning for research and production usage. It is named Harmonia, the Greek goddess of harmony, to reflect the spirit of federated learning; that is, multiple parities collaboratively build a ML model for the common good.
System Architecture
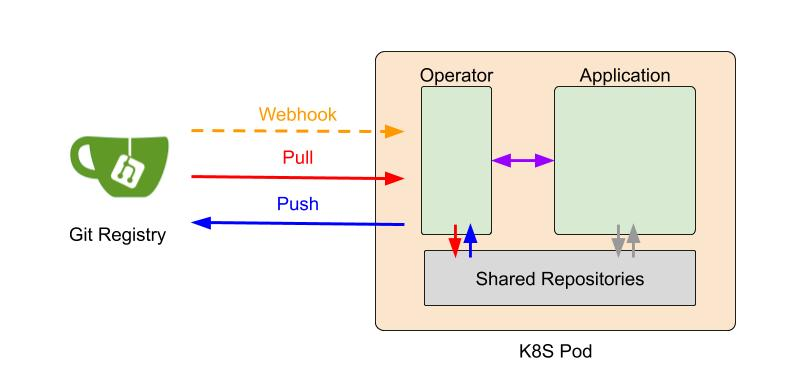
Figure 1: Harmonia system architecture
The design of the Harmonia system is inspired by GitOps. GitOps is a popular DevOp practice, where a Git repository maintains declarative descriptions of the production infrastructure and updates to the repository trigger an automated process to make the production environment match the described state in the repository. Harmonia leverages Git for access control, model version control and synchronization among the server and participants in a federated training (FL) run. An FL training strategy, global models, and local models/gradients are kept in the git repositories. Updates to these git respoitroies trigger FL system state transitions. This automates the FL training process.
An FL participant is activated as a K8S pod which is composed of an operator and application container. An operator container is in charge of maintaining the FL system states, and communicates with an application container via gRPC. Local training and aggregation functions are encapsulated in application containers. This design enables easy deployment in a Kubernetes cluster environment, and quick plug-in of existing ML (Machine Learning) workflows.
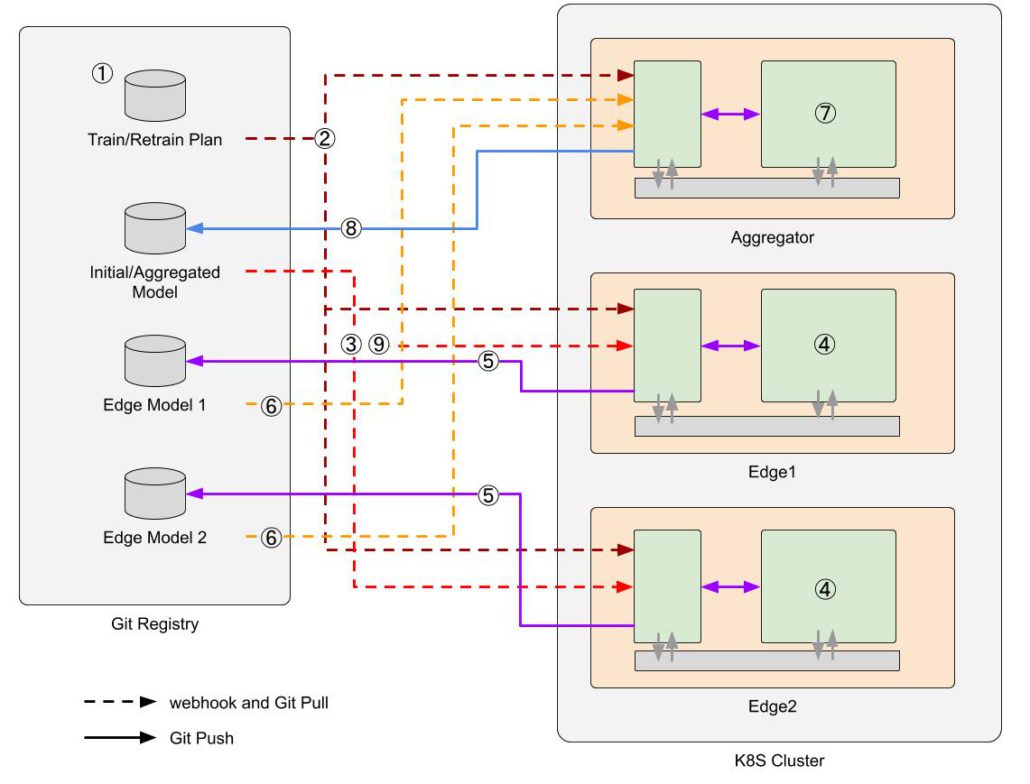
Figure 2: Illustration of two clients FL
Figure 2 illustrates the Harmonia workflow with two local training nodes. The numbers shown in the figure indicate the steps to finish a FL run in the first Harmonia release. To start a FL training, a training plan is registered in the git registry (1), and the registry notifies all the participants via webhooks (2). Two local nodes are then triggered to load a pretrained global model (3), and start local training with a predefined number of epochs (4). When a local node completes its local training, the resulting model (called a local model) is pushed to the registry (5) and the aggregator pulls this local model (6). Once the aggregator receives local models of all the participants, it performs model aggregation (7), and the aggregated model is pushed to the git registry (8). The aggregated model is then pulled to local nodes to start another round of local training (9). These processes are repeated until a user-defined converge condition is met, e.g., # of rounds. The sequence diagram of a FL run is shown in Figure 3.
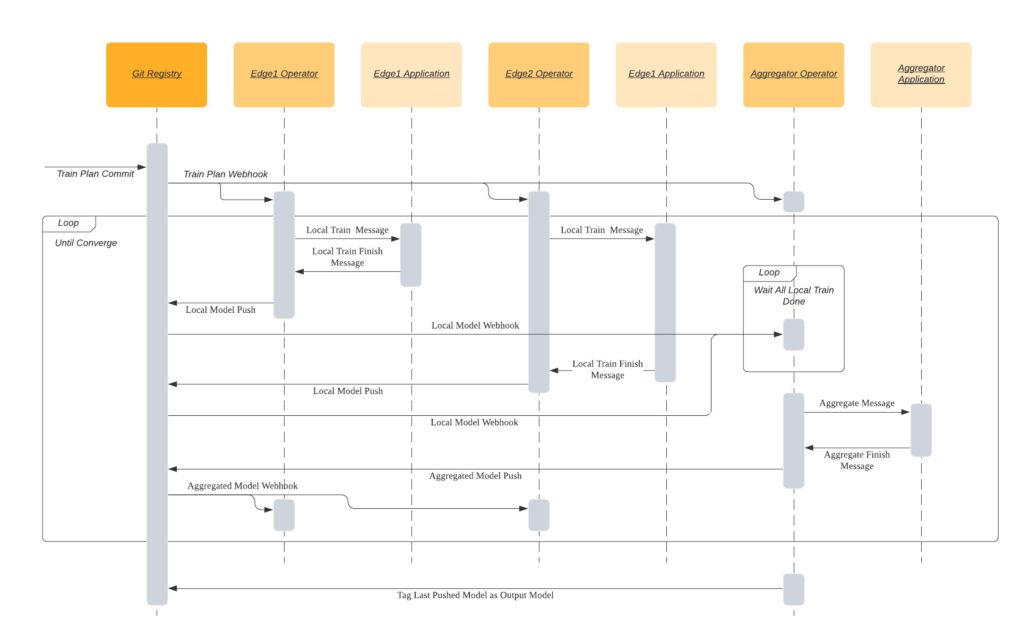
Figure 3: Sequence diagram
Below we detail the design of the Git repositories, workflows of an operator container for both an aggregator and a local node, and an application container.
Git Repositories
We have three types of repositories in registry:
- Training Plan: it stores the required parameters for a FL run. The training plan is a json file named json :
{
“edgeCount”: 2,
“roundCount”: 100,
“epochs”: 100
}
- Aggregated Model: it stores aggregated models pushed by the aggregator container. The final aggregated model is tagged with inference-<commit_hash_of_train_plan>.
- Edge Model: these repositories store local models pushed by each node separately.
Operator
Edge and aggregator operator containers control FL states. In Figure 4 and Figure 5, we show the workflow of an edge and aggregator operator, respectively.
Edge Operator
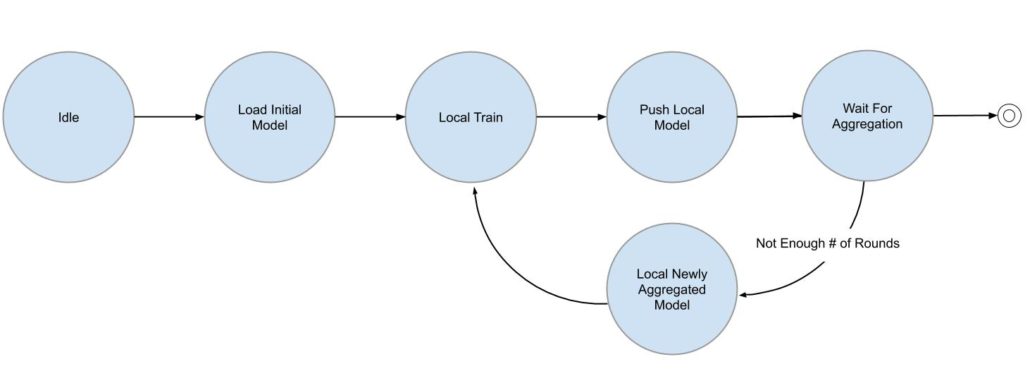
Figure 4: Workflow in an edge node
When a training plan is registered at Git, an edge node starts a training process with local data. The resulting new local model weights are pushed to the git registry, and an edge node then waits for the aggregator to merge new model updates from all participating edge nodes. Another round of local training is performed once the aggregated model is ready at the git registry. This process repeats until it reaches the number of rounds specified in the training plan.
Aggregator Operator
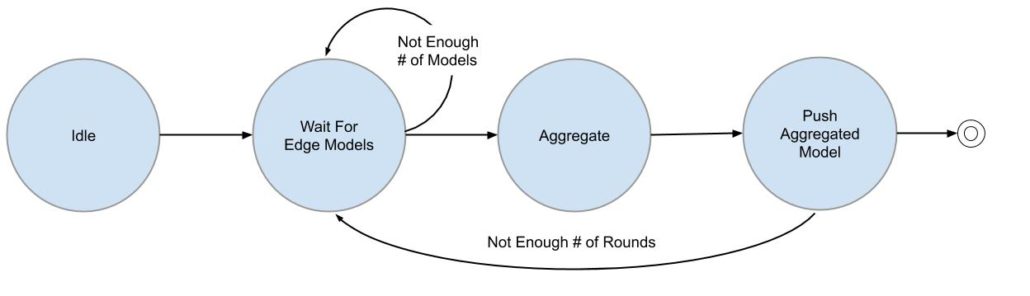
Figure 5: Workflow in Aggregator
For a new FL run, an aggregator operator starts with a state waiting for all edges finishing their local training and notifies the application container in the aggregator server to perform model aggregation. A newly aggregated model is pushed into the git registry. The process iterates until it reaches the number of rounds specified in the training plan.
Application
Local training or the model aggregation task is encapsulated in an application container, which is implemented by users. An application container communicates with an operator container with gRPC protocols. Harmonia works with any ML framework. In the SDK, we provide an application container template so a user can easily plug in their training pipeline and aggregation functions and don’t need to handle gPRC communication.
Experiments
We demonstrate the usage of Harmonia with pneumonia detection on chest x-rays . The experiment is based on the neural network architecture developed by Taiwan AI Labs.
We took the open dataset RSNA Pneumonia dataset [1], and composed two different FL datasets. In this experiment, we assumed 3 hospitals. We first randomly split the whole dataset into a model training set (80%) and a testing set (20%). In the first FL dataset, we randomly assign training data to edges. In a real-world scenario, data from different hospitals are often non-IID (Independent and Identically Distributed). Therefore, in the second FL dataset, the ratio of positive data and negative data on each edge are set differently. Table 1 shows the number of positive and negative training data for centralized training, federated training with IID and non-IID, respectively.
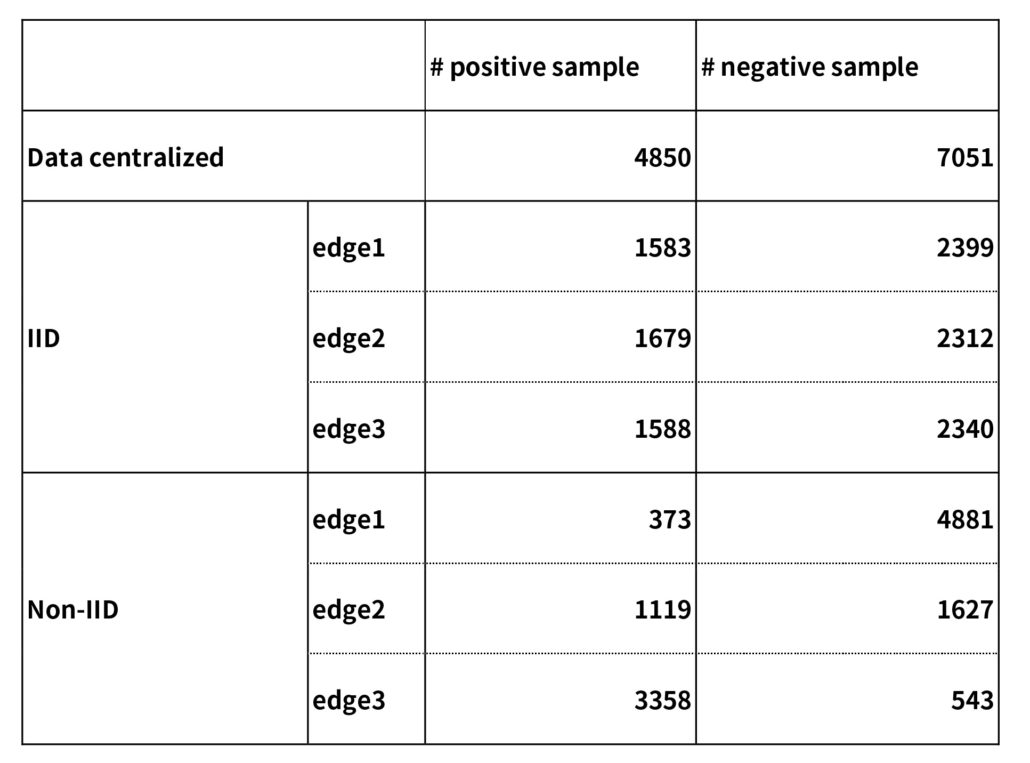
Table 1: Number of positive and negative training data of each training method
We adopted Federated Averaging (FedAvg) as our aggregation method [2] in this experiment. Local models are averaged by the aggregator proportionally to the number of training samples on each edge. Edges trained for one epoch in each round and the total number of epochs is the same as centralized training.
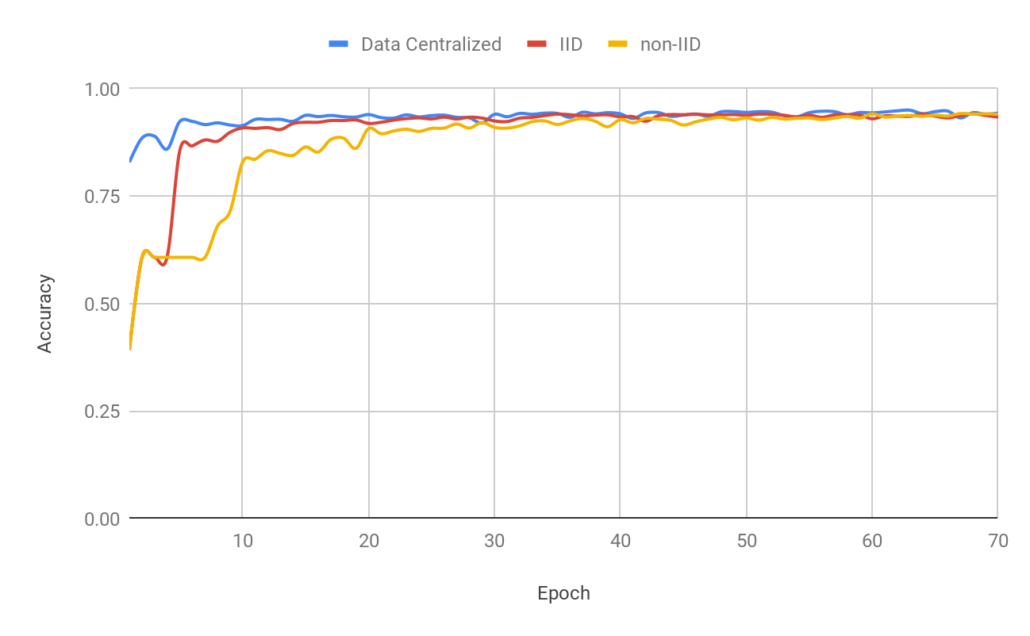
Figure 5: Classification accuracy
The results are shown in Figure 5. Both IID and non-IID FL could achieve comparable classification accuracy compared to centralized training, but they take more epochs to reach convergence for the non-IID dataset. We can also observe that non-IID FL converges slower than IID.
Privacy Module
To enforce Differential Privacy (DP), Harmonia provides a pytorch-based package, which implements two types of DP mechanisms. The first one is based on the algorithm proposed in [3, 5], a differentially-private version of the SGD, which randomly adds noises to SGD updates. Users can simply replace the original training optimizer to the DPSGD optimizer provided by Harmonia. The second technique is known as the Sparse Vector Technique(SVT) [4], which protects models by sharing distorted components of weights selectively. To adopt this privacy protection mechanism, a user could pass a trained model into the ModelSanitizer function provided by Harmonia.
Releases
The first release includes Harmonia-Operator SDK (https://github.com/ailabstw/harmonia) and differential privacy modules (https://github.com/ailabstw/blurnn). We will continue to develop essential components in FL (e.g., participant selection), and enable more flexible ways of describing FL training strategies. We welcome contributions of new aggregation algorithms, privacy mechanisms, datasets, etc. Let’s work together to flourish the growth of federated learning.
References
[1] RSNA Pneumonia Detection Challenge. https://www.rsna.org/en/education/ai-resources-and-training/ai-image-challenge/RSNA-Pneumonia-Detection-Challenge-2018
[2] Communication-Efficient Learning of Deep Networks from Decentralized Data. Brendan McMahan et al., in Proceedings of AISTATS, 2017
[3] Deep Learning with Differential Privacy. Martín Abadi et al., in Proceedings of ACM CCS, 2016
[4] Understanding the sparse vector technique for differential privacy. Min Lyu et al., in Proceedings of VLDB Endowment, 2017
[5] Stochastic gradient descent with differentially private updates. Shuang Song et al., in Proceedings of GlobalSIP Conference, 2013