Music Analysis for Automatic Music Composition: Source Separation and Music Transcription
AI needs a lot of music examples to learn to compose music. The quality and diversity of the music examples can be the key to the success of the AI. Typically, researchers begin with training an AI music composition model by learning from symbolic music data such as MIDI files. This is how we developed the AI Jazz bass player introduced in our last blog post.
However, relying on the MIDI files as the major data source has a few clear limitations. First, not all the music out there has MIDI files that are publicly and widely available. This is especially the case for certain music genres such as Jazz, which features improvisation. Second, MIDI files are notoriously noisy [1]. A great effort is needed in preprocessing and cleansing the MIDI data before they can be used to train a machine learning model. Such a process may come with assumptions, simplifications, and imprecisions that limit the performance of the resulting AI model. Third, not all MIDI files contain performance-level attributes of music such as the velocities (dynamics) and microtimings (timing offsets) of the musical notes. The music generated may sound mechanical and not expressive enough [2].
To free Yating from such limitations, we have a team of data engineer, machine learning engineer and musicians that are working on tasks that can be in general referred to as music analysis, or music information retrieval. Our goal is to enable Yating to learn to compose and perform music directly from audio recordings of music performances, an approach the Google Magenta team is also exploring [3]. This new approach, when successful, can unlock many important potentials of AI music composition models.
While the Google Magenta team dealt with exclusively piano-only music in [3], we are interested in building a data processing pipeline that allows us to learn from music played by any instruments.
In doing so, we are building an “AI Listener” that can (one day) comprehend the content of arbitrary music signals as good as well-trained human listeners. The first two music analysis tasks we are focusing on now are “source separation” and “music transcription,” for the output of such models, after some other processing, can be used to AI music composition models.
A core task of source separation [4] is to isolate out the sounds of specific instruments from an audio mixture. For example, a Jazz piano trio usually consists of the sounds played by a pianist, a bass player and a drummer. While human ears can focus on the sounds from one of the instruments while listening to the music, it may be hard for a machine to do so, as the sounds from these instruments (musical sources) have been mixed together in the audio signal.
The task of music transcription [5], on the other hand, can be said as converting music from the audio domain (audio signal) to the symbolic domain (e.g., MIDI file). For single-instrument music, we may want to transcribe the pitch, onset/offset timings, and even the velocity of all the musical notes. For multi-instrument music, the task is even challenging as we need to decide which note is played by which instrument.
For now, we built a source separation model to isolate out the piano track from an audio mixture, and a music transcription model to convert the (separated) piano track from the audio domain to the symbolic domain. We focus on the piano now because there are more public-domain datasets for piano transcriptions (such as the MAESTRO dataset [3] and the MAPS database [6]). But, thanks to the source separation model, we can learn from not only piano-only music but also multi-instrument music that contains piano.
In other words, the two models are cascaded to transcribe the piano part of an audio mixture. The transcription result can then be used to train an AI compoisition model. This process is illustrated below.
![]()
We present below four examples showing the performance of our models in isolating out and transcribing the piano. In each set of audio files, we show the original audio mixture first, then the separated piano track, and finally the transcribed result. The transcribed result is rendered using an electric piano sound font by a VSTi. We also show the pianoroll demonstrating the transcription result for each song.



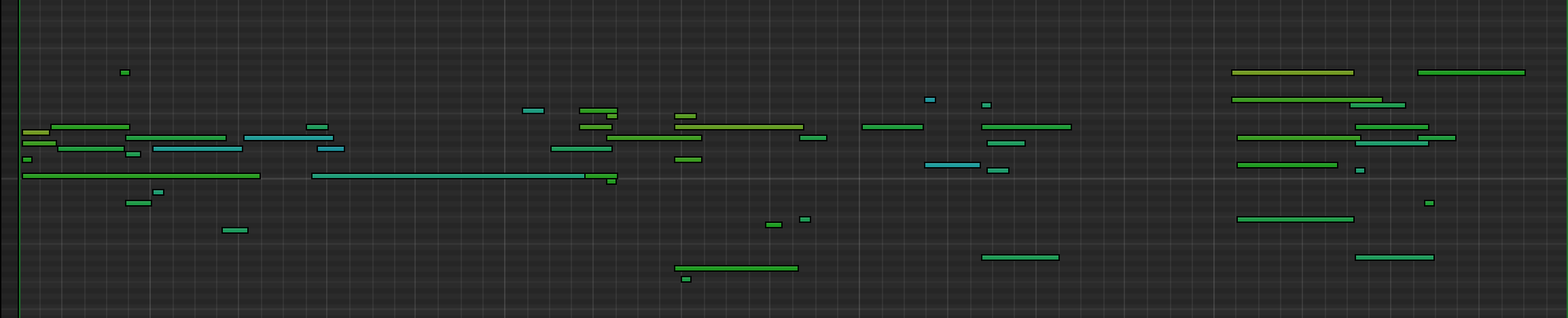
(Please note that, because our music transcription model does not predict the usage of sustain pedal thus far (this is a function we will add soon), we occasionally apply sustain pedal by hand to the transcribed result in the above examples.)
In general, the separation result is fairly good. The separation model removes the sounds from other instruments, and the remaining piano sounds do not suffer from distortion or other artefacts. This is quite remarkable, as we notice that this may be the first demonstration of a successful piano source seperation model in the world—people working on musical source seperation usually aim to isolating out the singing voice, drum, and bass (see the SiSEC challenge [7] for example), not the piano. We are currently extending the model to deal with other instruments, such as the guitar.
The transcription result is not perfect yet it already seems feasible to be used for training music composition models.
While it’s still our ongoing work to leverage such transcription result for training AI music composition models, our in-house musicians already find ways to play with the separated piano tracks. Check the video below to see how they used the output of our separation model for making hip-hop style music.
References:
[1] C Raffel and DPW Ellis, “Extracting Ground-Truth Information from MIDI Files: A MIDIfesto,” in Proc. International Society for Music Information Retrieval Conference (ISMIR), 2016. (link)
[2] B Wang and YH Yang, “PerformanceNet: Score-to-audio Music Generation with Multi-band Convolutional Residual Network,” in Proc. AAAI Conference on Artificial Intelligence (AAAI), 2019. (link)
[3] C Hawthorne, A Stasyuk, A Roberts, I Simon, CZ Anna Huang, S Dieleman, E Elsen, J Engel, and D Eck, “Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset,” in Proc. International Conference on Learning Representations (ICLR), 2019. (link)
[4] JY Liu and YH Yang, “Dilated Convolution with Dilated GRU for Music Source Separation,” in Proc. International Joint Conference on Artificial Intelligence (IJCAI), 2019. (link)
[5] C Hawthorne, E Elsen, J Song, A Roberts, I Simon, C Raffel, J Engel, S Oore, and D Eck, “Onsets and Frames: Dual-Objective Piano Transcription,” in Proc. International Society for Music Information Retrieval Conference (ISMIR), 2018. (link)
[6] V Emiya, R Badeau, B David, “Multipitch estimation of piano sounds using a new probabilistic spectral smoothness principle,” IEEE Transactions on Audio, Speech and Language Processing, 2010. (link)
[7] https://sigsep.github.io/datasets/musdb.html
By: Jen-Yu Liu, Chung-Yang Wang, Tsu-Kuang Hsieh and Yi-Hsuan Yang (Taiwan AI Labs Yating/Music Team)