Guitar Transformer and Jazz Transformer
At the Yating Music Team of the Taiwan AI Labs, we are developing new music composing AI models extending from our previous Pop Music Transformer model (see the previous blog). In October 2020, we are going to present two full papers documenting some of our latest result at the International Society for Music Information Retrieval Conference (ISMIR), the premier international conference on music information retrieval and music generation.
The first paper, entitled “Automatic composition of guitar tabs by Transformers and groove modeling,” talks about a Guitar Transformer model that learns to generate guitar tabs.
- paper: https://arxiv.org/abs/2008.01431 (pre-print)
- demo: https://ss12f32v.github.io/Guitar-Transformer-Demo/
Here are two tabs in the style of guitar fingerstyle generated fully automatically by this model; no human curation involved.
The highlight of this work is to design and incorporate what we call the “grooving” tokens to the representation we use to represent a piece of symbolic guitar music. Groove, which can be in general considered as a rhythmic feeling of a changing or repeated pattern, or “humans’ pleasurable urge to move their bodies rhythmically in response to music,” is not explicitly specified in either a MIDI or TAB file. Instead, groove is implicitly implied as a result of the arrangement of note onsets over time. Therefore, existing methods for representing music do not involve the use of groove-related tokens.
What we did is to apply music information retrieval (MIR) techniques to extract a 16-dimensional vector representing the occurrence of note onsets over 16 possible equally-spaced quantized positions of a bar, and then use the classical kmeans algorithm to cluster such 16-dim vectors from all the bars from all the pieces of our training data, leading to k (=32) clusters (we need clustering for otherwise there will be too many unique such 16-dim vectors). We then treat these cluster IDs as “grooving tokens” and assign a grooving token to each bar of a music piece. In this way, what our Transformer model (specifically, we use Transformer-XL) sees during model training would be not only the note-related tokens but also such bar-level grooving tokens. It turns that this improves quite a lot the quality of the generated music, compared to the baseline model that does not use grooving tokens.
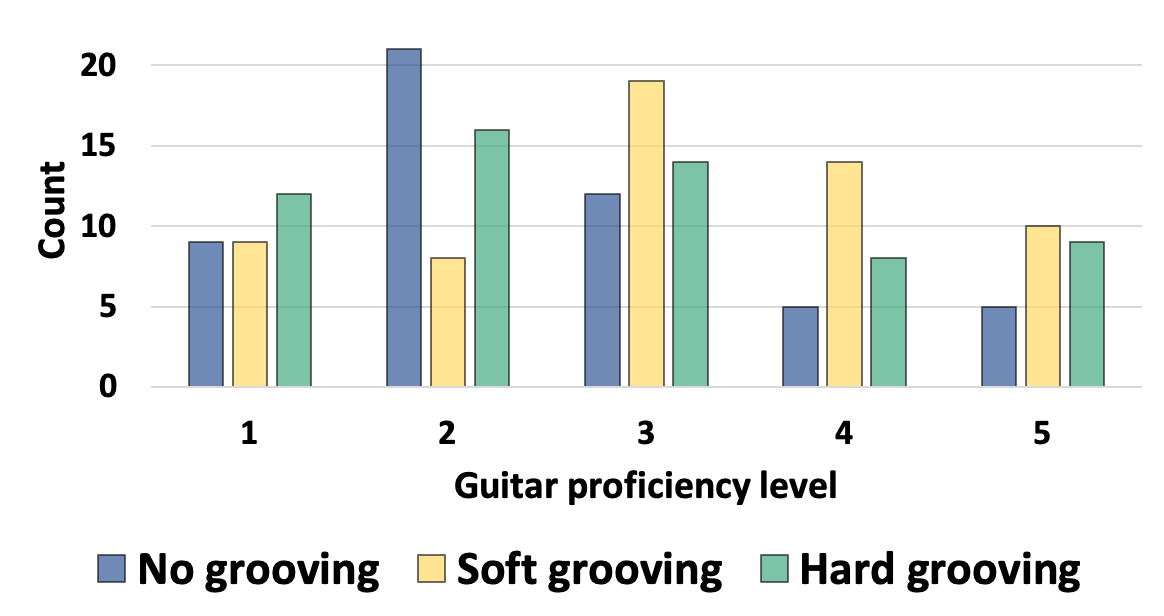
The following figure shows the result of a user study asking subjects to choose the best among the three continuations generated by different models, with or without the grooving tokens, given a short human-made prompt. The result is broken down according to the self-report guitar proficiency level of the subjects. We can see that the professionals are aware of the difference between the grooving-agnostic model and the two groove-aware models (we implemented two variants here, a `hard grooving` model and a `soft grooving model`, which differ in the way we represent the musical onsets).
The second paper, entitled “The Jazz Transformer on the front line: Exploring the shortcomings of AI-composed music through quantitative measures,” talks about a Jazz Transformer model that learns to generate Jazz-style lead sheets, using the Jazzomat dataset.
- paper: https://arxiv.org/abs/2008.01307 (pre-print)
- code: https://github.com/slSeanWU/jazz_transformer
- code2: https://github.com/slSeanWU/MusDr
The focus of this paper can be said to be about the development of objective metrics tailored for symbolic music generation tasks (namely, not for general sequence generation tasks). Specifically, we proposed the following metrics:
- Pitch Usage: Entropy of 1- & 4-bar chromagrams;
- Rhythm: Cross-bar similarity of grooving patterns;
- Harmony: Percentage of unique chord trigrams;
- Repeated structures: Short-, mid-, & long-term structureness indicators (computed from the fitness scape plot);
- Overall musical knowledge: Multiple-choice continuation prediction (given 8 bars, predict the next 8 bars).
Implementation of these evaluation metrics can all be found in the `MusDr` repository listed above. It has also been integrated into `MusPy,` an open source Python library for symbolic music generation developed by Hao-Wen Dong et al at UCSD.
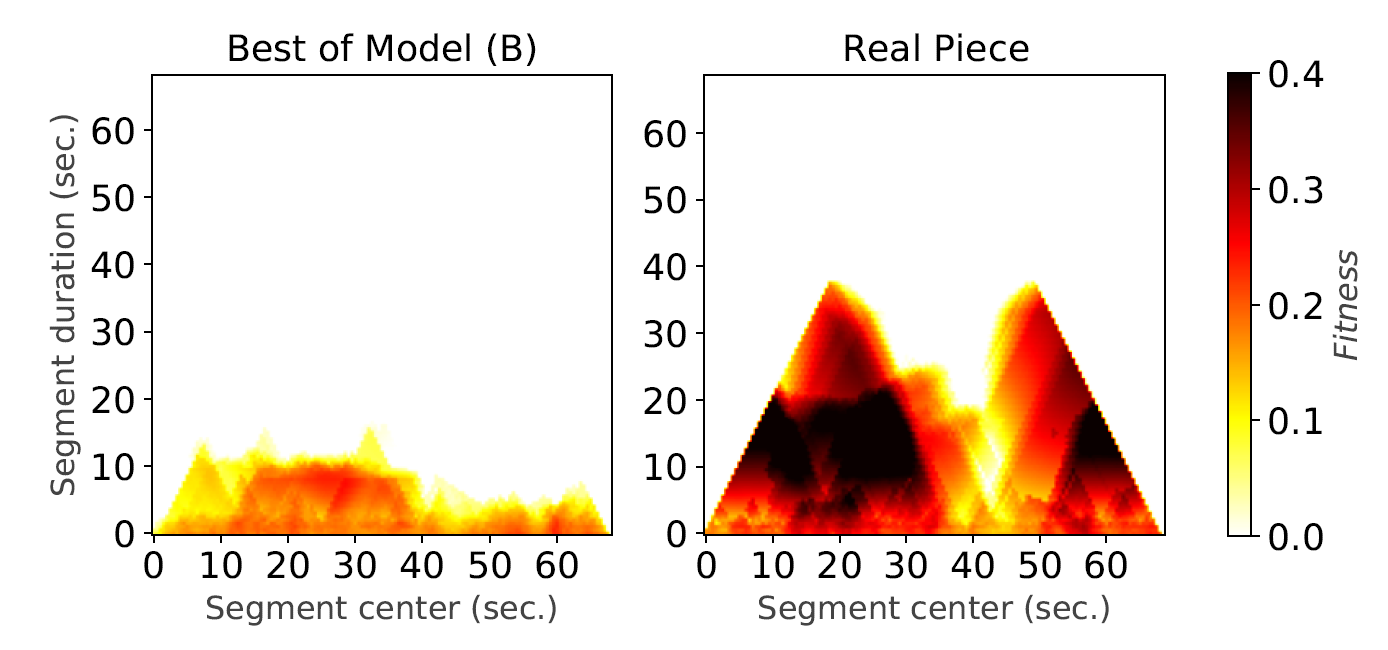
These objective metrics can help us gain some ideas about the quality of the machine-generated music, dispensing the need to run the expensive user studies too many times. These metrics also help elucidate the difference between machine-composed music and human-composed ones. For example, from the structureness indicators, we can see clearly that Transformer-XL based music composing models, which represent a current state-of-the-art, still fall short of generating music with reasonable mid- and long-term structure. See the following figure for a comparison between the fitness scape plot of a piece composed by the Jazz Transformer (marked as `Model (B)’), and that of a human-composed one.
We are actively using these new metrics to guide and to improve our models. In particular, we are finding ways to induce structures in machine-composed music. Let us know if you like what we are doing and/or have some ideas to chat with us!
Ref:
[1] Yu-Hua Chen, Yu-Siang Huang, Wen-Yi Hsiao, and Yi-Hsuan Yang, “Automatic composition of guitar tabs by Transformers and groove modeling,” in Proc. Int. Society for Music Information Retrieval Conf. 2020 (ISMIR’20).
[2] Shih-Lun Wu and Yi-Hsuan Yang, “The Jazz Transformer on the front line: Exploring the shortcomings of AI-composed music through quantitative measures,” in Proc. Int. Society for Music Information Retrieval Conf. 2020 (ISMIR’20).
By: Yu-Hua Chen, Shih-Lun Wu, Yu-Siang Huang, Wen-Yi Hsiao and Yi-Hsuan Yang (Yating Music Team, Taiwan AI Labs)