Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions
Paper (ACM Multimedia 2020): https://arxiv.org/abs/2002.00212 (pre-print)
Code (GitHub): https://github.com/YatingMusic/remi
We’ve developed Pop Music Transformer, a deep learning model that can generate pieces of expressive Pop piano music of several minutes. Unlike existing models for music composition, our model learns to compose music over a metrical structure defined in terms of bars, beats, and sub-beats. As a result, our model can generate music with more salient and consistent rhythmic structure.
Here are nine pieces of piano performances generated by our model in three different styles. While generating the music, our model takes no human input (e.g., prompt or chord progressions) at all. Moreover, no post-processing steps are needed to refine the generated music. The model learns to generate expressive and coherent music automatically.
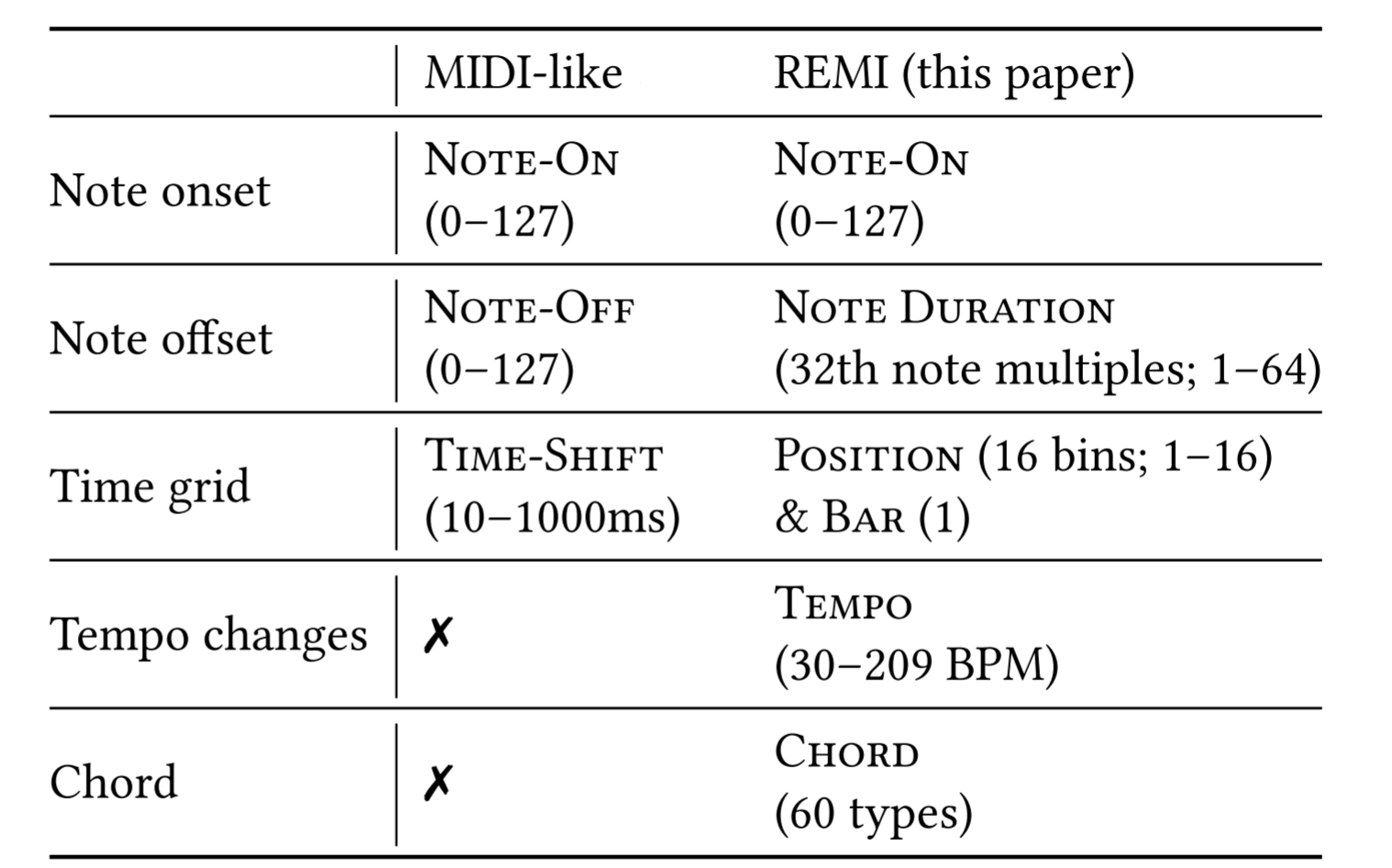
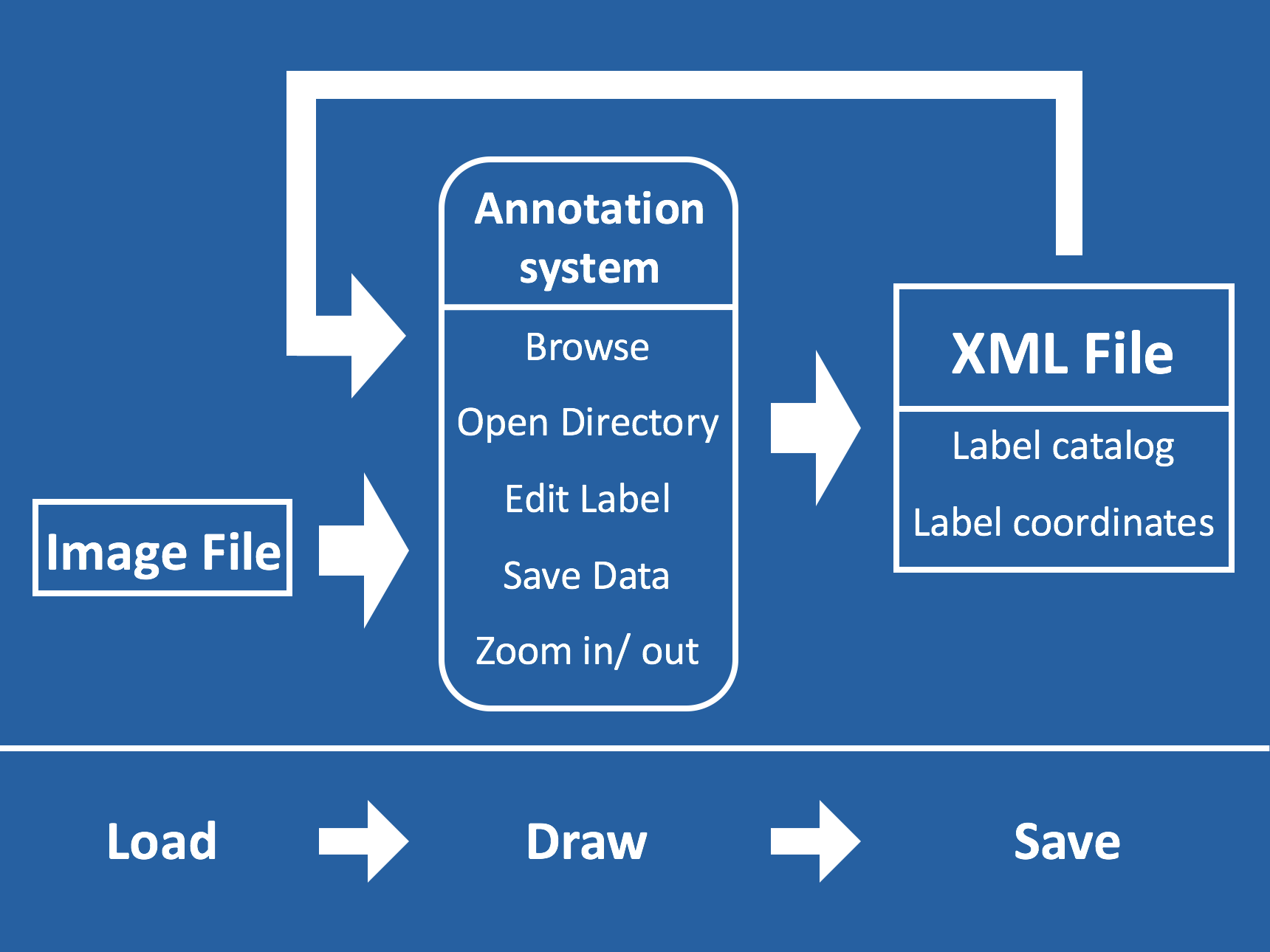
From a technical point of view, the major improvement we have made is to invent and employ a new approach to represent musical content. The new representation, called REMI (REvamped MIDI-derived events), provides a deep learning model more contextual information for modeling music than existing MIDI-like representation. Specifically, REMI uses position and bar events to provide a metrical context for models to “count the beats.” And, it uses supportive musical tokens capturing the high-level music information of tempo and chord. Please see the figure below for a comparison between REMI and the commonly-adopted MIDI-like token representation of music.
The new model can generate music with explicit harmonic and rhythmic structure, while allowing for expressive rhythmic freedom in music (e.g., tempo rubato). While it can generate chord events and tempo changes events on its own, it also provides a mechanism for human users to control and manipulate the chord progression and local tempo of the music being generated as they wish.
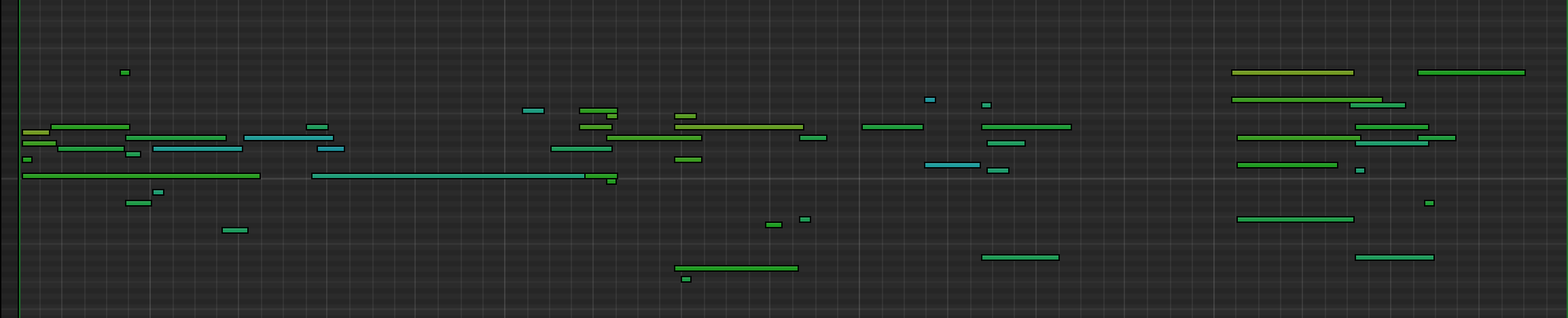
The figure below show the piano-rolls of piano music generated by two baseline models (the first two rows) and the proposed model (the last one), when these models are asked to “continue” a 4-bar prompt excerpted from a human-composed music. We can see that the proposed model continues the music better.
![]()
The figure below show the piano-roll of a generated piano music when we constrain the model not to use the same musical chord (F:minor) as the 4-bar prompt.
![]()
The paper describing this new model has been accepted for publication at ACM Multimedia 2020, the premier international conference in the field of multimedia computing. You can find more details in our paper (see the link below the title) and try the model yourself with the code we’ve released! We provide not only the source code but also the pre-trained model for developers to play with.
More examples of the generated music can be found at:
https://drive.google.com/drive/folders/1LzPBjHPip4S0CBOLquk5CNapvXSfys54
Enjoy listening!
By: Yu-Siang Huang, Chung-Yang Wang, Wen-Yi Hsiao, Yin-Cheng Yeh and Yi-Hsuan Yang (Yating Music Team, Taiwan AI Labs)







 Smart City workshop with
Smart City workshop with 