Azoospermia with Deep Learning Object Detection
Introduce Azoospermia
Azoospermia is a medical term implying the condition of no measurable sperm in a man’s semen. It is also the main challenge in male infertility. Azoospermia could be divided into two classes, including obstructive azoospermia(OA) and non-obstructive azoospermia(NOA). For OA, the testicular size and serum hormone profile are normal. On the other hand, NOA means the process of spermatogenesis is unusual, and to make a further diagnosis the doctor has to check the cell findings of testicular specimens. Originally, it took 2-3 days to complete a pathological diagnosis. In order to make the process more efficient, the Department of Urology of Taipei Veterans General Hospital has developed a standard process using the testicular touch print smear(TPS) technique to make real-time diagnoses. However, it would take a lot of time to learn the interpretation of TPS. Machine learning or deep learning technologies have applied to different kinds of medical images and have become a new field with many researchers involved. AI Labs cooperates with Dr. William J. Huang(黃志賢醫師) from Taipei Veterans General Hospital, to make AI assist surgeons in the reading of TPS slides. We aim to perform object detection techniques on testicular specimens to find 6 cells, including Sertoli cell, primary spermatocyte, round spermatid, elongated spermatid, immature sperm, and mature sperm. These cells are essential to determine different stages of azoospermia.
Implementation
In this task, our goal is to detect cells among the above 6 classes in one individual image, the desired outputs are accurate bounding boxes and their labels. Since there are no existing open-dataset for this work, we have to build our own dataset. Provided input images are 2D testicular specimens captured from an electron microscope, with ground truth boxes and labels. The cell dataset currently contains 120 images with over 4,500 cells, which are annotated and reviewed by Dr. Huang and his assistant. Considering input size, class number and performances, we use EfficientDet as our model to train a network to detect cells in TPS.
Example of input image with annotations. Different color means different class.
What is EfficientDet?
EfficientDet is the current state-of-the-art network for object detection. It is consists of a backbone network and a feature network. Inputs are feed into the backbone network; features would be extracted from different layers in backbone and sent to feature networks. Feature maps would be combined in different strategies depending on the network you used. At the end of the feature network, there are two heads with several layers that are used to predict final bounding box positions and class labels. In our setting, the EfficientDet uses EfficientNet pretrained on ImageNet as backbone and BiFPN as feature networks.
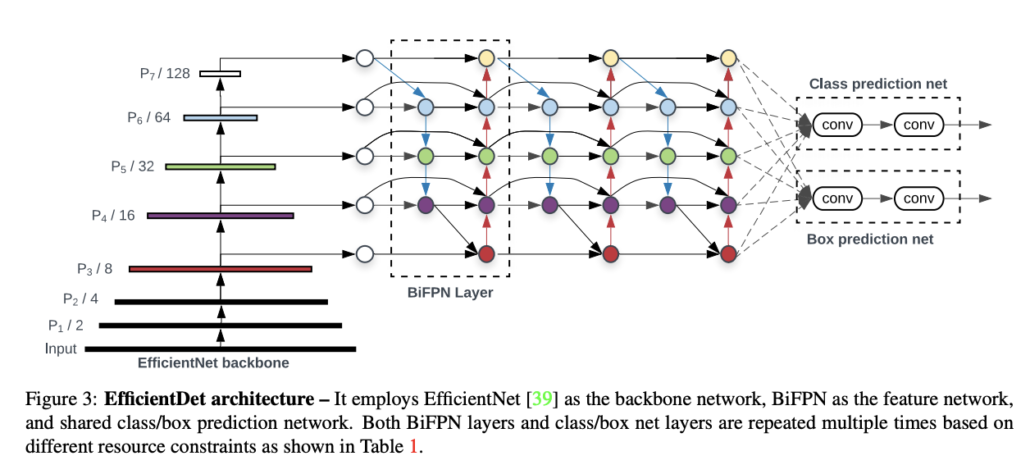
EfficicientDet Model Structure.
EfficientNet is a model that applies the compound scaling strategy to improve accuracy. While pursuing higher performance, researchers often scale up model width, depth or resolution. However, the results are often contrary to expectation if the model becomes too complicated. The authors of EfficienNet combined different scaling through Neural Architecture Search to find suitable composite, thus it is called compound scaling. There are 8 levels of EfficientNet in total, and we choose EfficientNet-B3 as our backbone considering the difficulty of our task, input size, and model size.
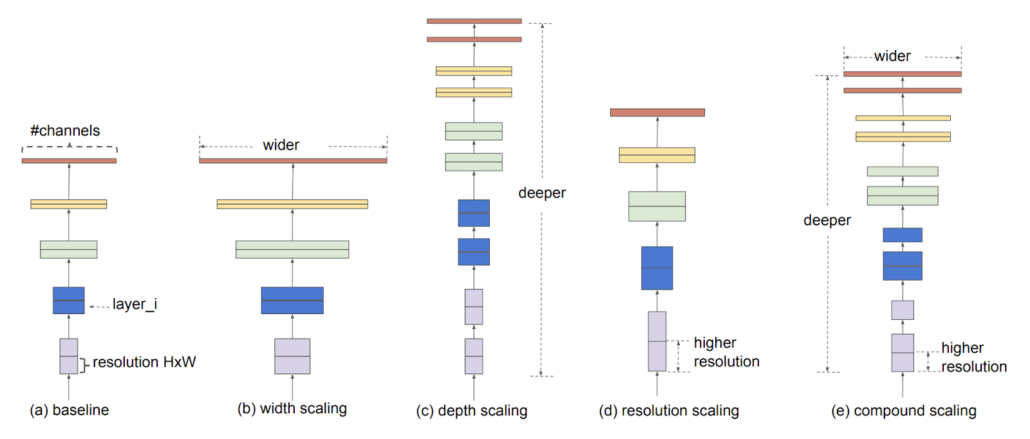
Illustration of compound scaling strategy.
BiFPN is a feature pyramid network(FPN) with both top down and bottom up paths to combine feature maps, while the original FPN has only top down path. The purpose is to enhance the feature expression, so the bounding box regression and classification could perform better.
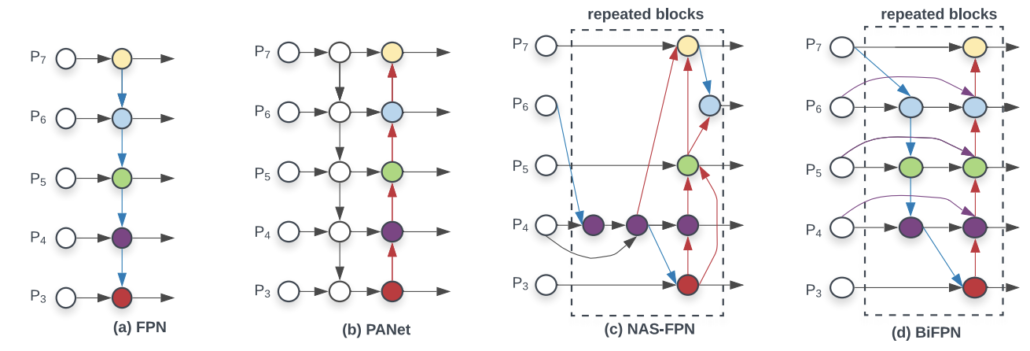
Comparison of different FPNs.
Implementation Details
There are some modifications that we have done to apply EfficientDet on our data. First, we reduce the size of anchor and the intersection of union(IoU) threshold for finding anchors correspond to ground truth boxes. The reason is that the smallest cell size is only around 8px, which is much smaller than the default base anchor size 32px. Also, since the boxes are quite small, matching ground truth boxes and anchors under a looser condition would make it easier to learn. Furthermore, we sample K matched anchors instead of all candidates for computing losses and update, K=20. Image size is set to 768×1024.
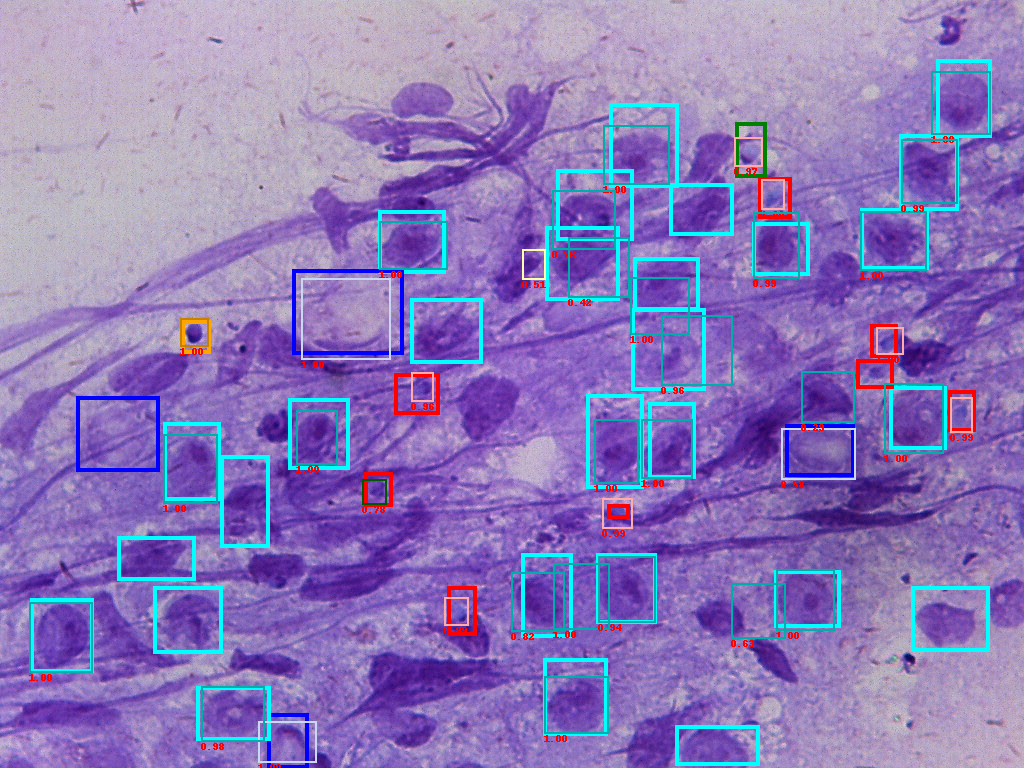
For the small dataset with 108 training images and 12 testing images, we are able to reach a mAP 71%, recall 76% performance.
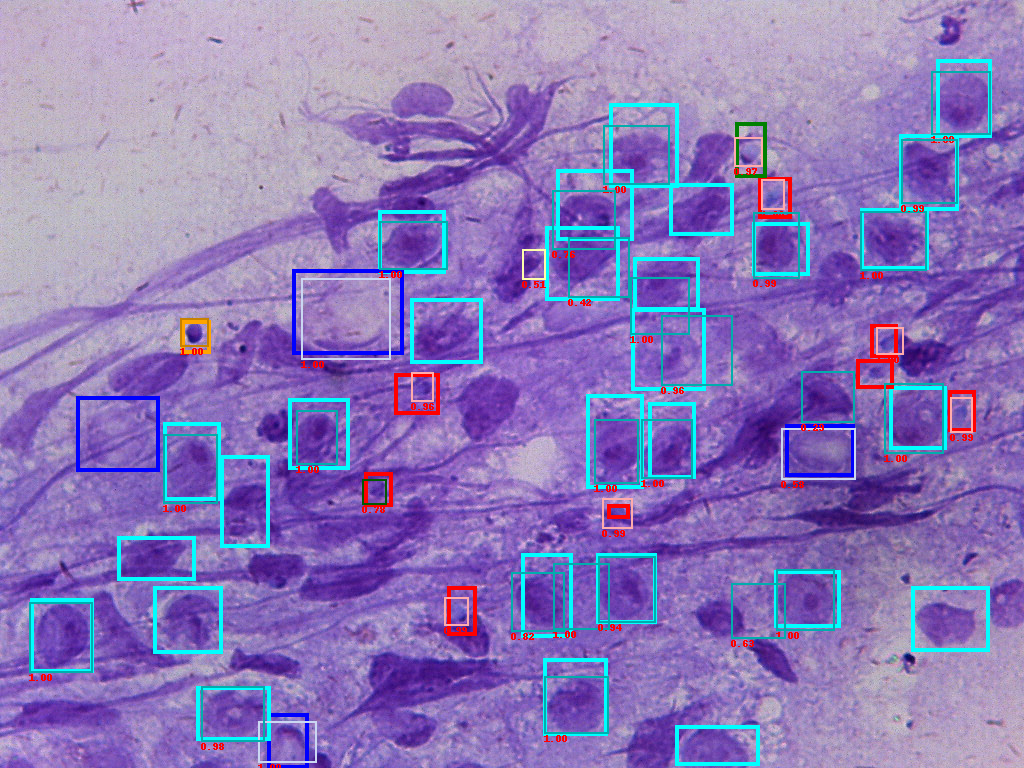
Figure of input ground truth data(bold frames) and predicted boxes(thin frames). The number is confidence score.
Conclusion
We demonstrate that modern machine learning/deep learning methods could apply to medical images, and are able to achieve satisfying performance. This model would help the surgeon to interpret the smear more easily, and even speed up the surgery as we are actively working on improving the model with more data.
Ref:
[1] Tan, M. & Le, Q.. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Proceedings of the 36th International Conference on Machine Learning, in PMLR 97:6105-6114
[2] M. Tan, R. Pang and Q. V. Le, “EfficientDet: Scalable and Efficient Object Detection,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020, pp. 10778-10787, doi: 10.1109/CVPR42600.2020.01079.

