Compound Word Transformer: Generate Pop Piano Music of Full-Song Length

Over the past months, we attempted to let transformer models learn to generate full-song music, and here is our first attempt towards that, the Compound Word Transformer. A paper describing this work is going to be published as a full paper at AAAI 2021, the premier conference in the field of artificial intelligence.
You can find a preprint of the paper, and the open source code of the model, from the links below:
We made two major improvements in this work: First, a new representation – Compound Word is presented, which can let transformer models accept longer input sequence. Second, we adopt the linear transformer as our backbone model. The memory complexity of linear transformer scales linearly with respect to the sequence length, and such property enables us to train longer sequences on limited hardware budgets.
To our best knowledge, this is also the first AI model that deals with music at the full-song scale, instead of music segments. Currently, we let our model focus on learning to compose pop piano music, whose average length is approximate 3 to 5 minutes long. Before diving into the technical details, let’s listen to some generated pieces:
All clips above are generated from scratch. Aside from this, our model can also understand the lead sheet, which conveys only melody line and chord progression, and translate it into an expressive piano performance:
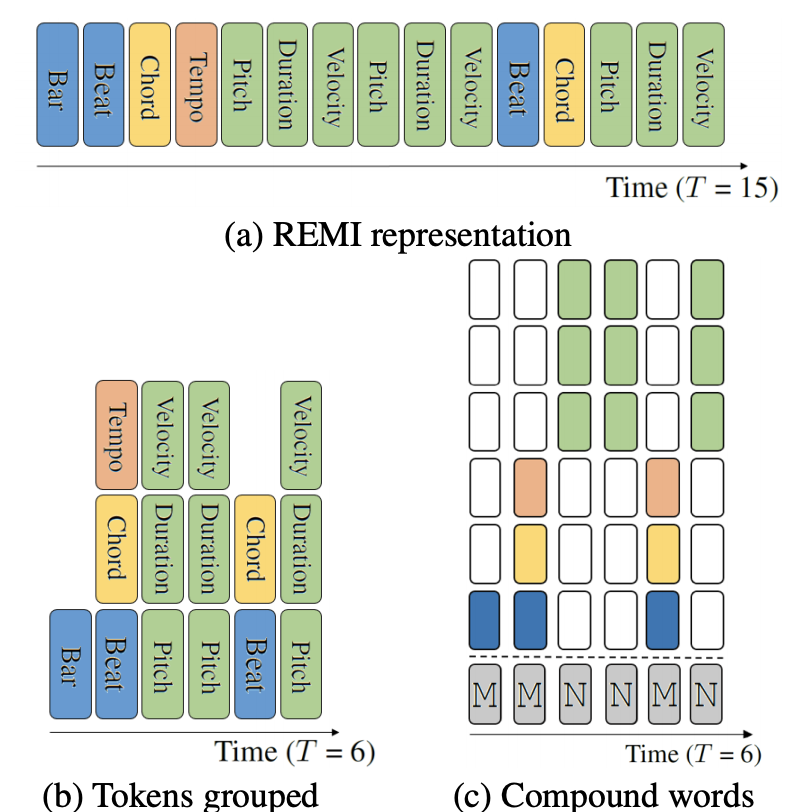
How do we nail it? We reviewed our previous work REMI and found the way to represent music can be further condensed. If the required sequence length is shorter, we can feed longer music into the model. The figure below displays the process of how we convert REMI into Compound Words representation. Instead of predicting only one token per timestep, CP groups consecutive and related tokens and predict them at once so as to reduce the sequence length. Each field of CP is related to a certain aspect/attribute of music, such as duration, velocity, chords, and etc
For modeling such CP sequences, we design the specialized input and output modules of the transformer. The figure below illustrates the proposed architecture in action at a certain timestep. On the right half part, where the model makes token prediction, you can see that there are multiple feedforward heads, each accounting for a field of CP, which corresponds to a single row of CP shown in the figure above. On the left half part, each field of CP has its own token embedding, which will be concatenated as the vector and then reshaped by a linear layer, to become the final input of the transformer.
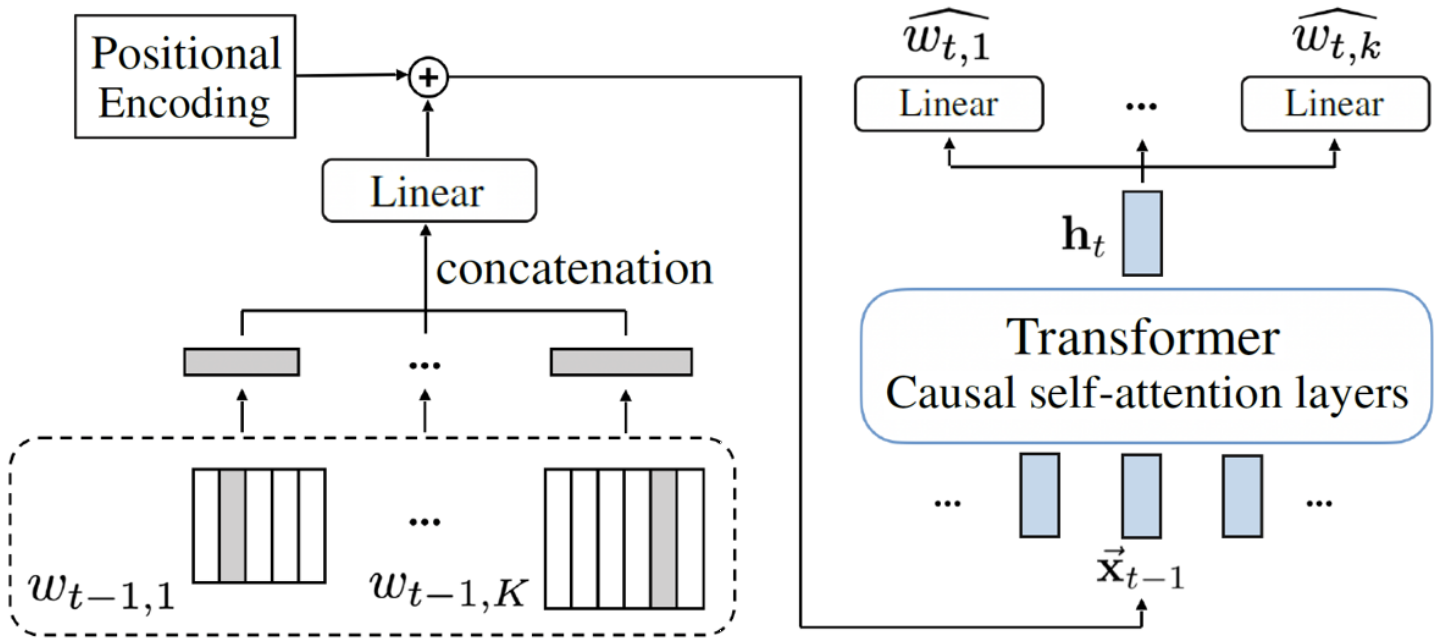
Because each head only concentrates on a certain field of CP, we can have more precise control when either modeling or generating music. For example, in training, we can assign different sizes of embedding to tokens of different types, according to the difficulty level associated with each type of token. We set larger for harder ones like duration and pitches, and smaller for the easier ones like beats and bars. In the inference time, we can adopt different sampling policies. For example, we can use larger temperature to have more randomness in the prediction of velocity tokens; and smaller temperature for pitch tokens to avoid mistakes.
The proposed model shows good training and inference efficiency. Now we can train our model on a single GPU with 11GB memory within just one day. In inference time, to generate a 3-minute song takes only about 20 seconds, which is much faster than real-time.
Learning to generate full songs means that the model can take the whole song as input and knows when to start when generation. However, the music generated by the current model still does not exhibit clear structural patterns, like AABA form, or repetitive phrases, etc. We are working on this, hoping one day our AI can write a hit song.
More examples of the generated music can be found at:
https://drive.google.com/drive/folders/1G_tTpcAuVpYO-4IUGS8i8XdwoIsUix8o?usp=sharing
By: Wen-Yi Hsiao, Jen-Yu Liu, Yin-Cheng Yeh, Yi-Hsuan Yang (Yating Music Team, Taiwan AI Labs)

