MuseMorphose: Music Style Transfer with A Transformer VAE
At Taiwan AI Labs, we are constantly pushing the frontier of deep music generation models. In the past year, we have rolled out Guitar Transformer (blog), which can compose human-readable guitar tabs with plausible fingerings, and Compound Word Transformer (blog), which vastly accelerated model training and inference thanks to carefully re-engineered music representation. Today, proudly making its debut is MuseMorphose, our brand new model for music style transfer.
Unlike our previous works, which offered limited possibilities for user interaction, MuseMorphose is designed to extensively engage users in the machine creative process. With MuseMorphose, one may input his/her favorite song, the length of which unlimited, and set two musical style attributes, namely, rhythmic intensity and polyphony (i.e., harmonic fullness), of every bar to his/her desired level (0~7 possible). The model will then re-create the song, taking into account the user-specified sequence of bar-level style attributes.
Listening Samples
To showcase MuseMorphose’s capabilities, let us present some of its compositions first!
In the upper example, we feed the famous 8-bar theme of Mozart’s “Twinkle, Twinkle, Little Star” to the model, and ask it to generate a style-transferred version with increasing rhythmic and harmonic intensities (going up by 1 level per bar). For the next one, we choose an 8-bar excerpt from our AILabs1K7 pop song dataset (published here) and pick three drastically different style settings for MuseMorphose to wield its creativity.
Across all the samples, MuseMorphose responds precisely to the style settings. What’s more, it sticks faithfully to the musical flow of input song while adding its own creative and harmonious touches.
MuseMorphose: The Model
Now that we have had some pleasant music, it is time to delve into the technical underpinnings of MuseMorphose.
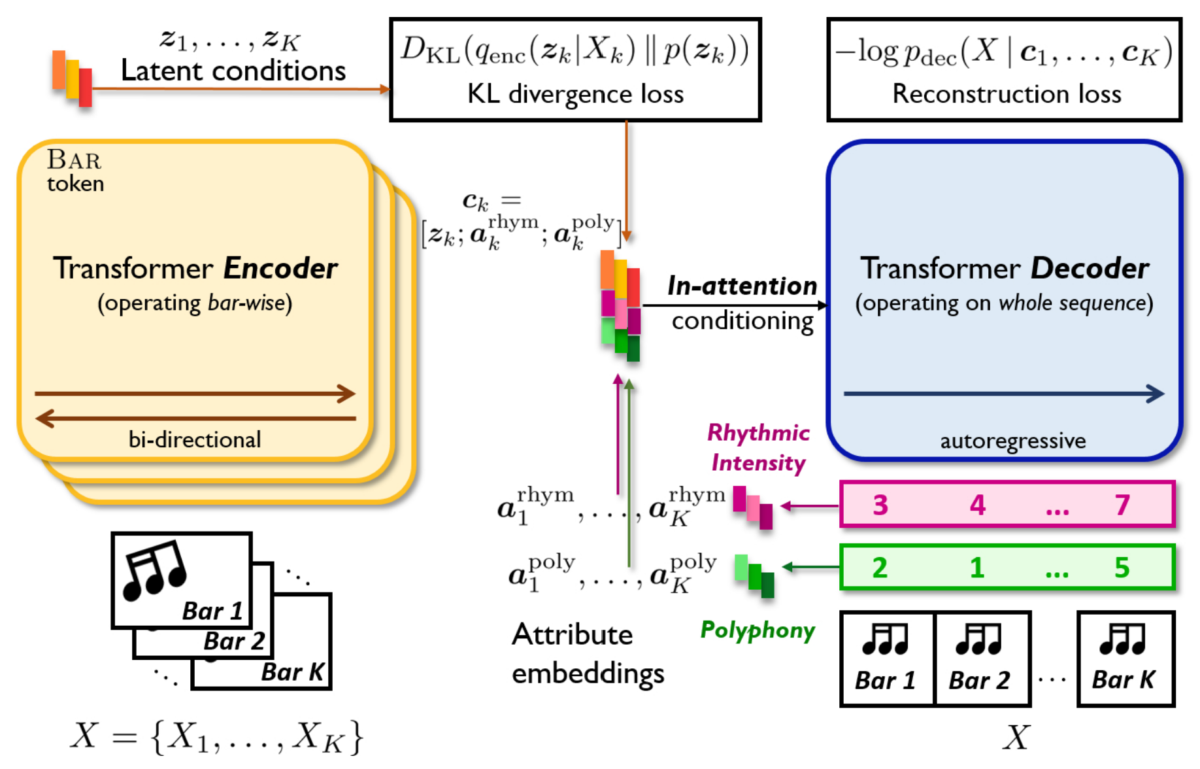
Architecture of MuseMorphose
MuseMorphose is based on two popular deep learning models for music generation: Variational Autoencoder (VAE), and Transformer. VAE (see also: MusicVAE & Attr-Aware VAE) grants users the freedom to harness the generation through operations on its learned latent space, much like we have shown in the examples; however, its RNN backbone greatly limits the length of music it can model.
Transformer (check out: Music Transformer & MuseNet), on the other hand, can generate music of up to 5 minutes long, but its conditional generation use cases remain underexplored. People could only use global condition tokens to affect a composition’s style or instrumentation, or, in some other cases, they have to supply a full melody/track for the model to come up with an accompaniment. It has not been possible to freely edit a piece according to its high-level musical flow. Therefore, we integrate the two models to construct MuseMorphose, which exhibits both of their strengths, and gets rid of their weaknesses.
In MuseMorphose, a Transformer encoder is tasked with extracting the musical skeleton of each bar in a piece as vectors (called “latent conditions” in the figure above). Then, these skeletons are concatenated with bar-level style inputs from the user, i.e., the rhythmic intensity and polyphony levels, mapped to learned embedding vectors. Finally, the concatenated conditions enter sequentially, i.e., bar by bar, into a Transformer decoder through the in-attention mechanism developed by us, to produce the style-transferred piece.
This asymmetric encoder-decoder design ensures the fine granularity of conditions, and maintains Transformer’s inherent ability to generate long sequences. Moreover, the in-attention mechanism, which injects each bar-level condition to corresponding timesteps and all layers of the Transformer decoder, is the key to effective conditioning.
Further Materials
- Paper (preprint): arxiv.org/abs/2105.04090
- Demo website: slseanwu.github.io/site-musemorphose
- Open-source code: github.com/YatingMusic/MuseMorphose
You may take a look at our paper to find more discussions on the architecture design, training objective, and evaluation. Our demo website provides even more compositions by MuseMorphose, as well as those by the baselines it outperforms, for you to listen. Want to compose some music with MuseMorphose? No problem! Just check out our open-source implementation and pre-trained checkpoint.
If you find our work exciting, and have some thoughts/suggestions about it (e.g., what other style attributes may be added to MuseMorphose), feel free to drop us a mail. We are definitely looking forward to a lively discussion.
By: Shih-Lun Wu, Yi-Hsuan Yang (Yating Music Team, Taiwan AI Labs)
