The Challenge of Speaker Diarization
Introduction
Speaker Diarization is the task to partition audio recordings into segments corresponding to the identity of the speaker. In short, a task to identify “who spoke when”. Speaker diarization can be used to analyze audio data in various scenarios, such as business meetings, court proceedings, online videos, just to name a few. However, it is also a very challenging task since characteristics of several speakers have to be jointly modelled.
Traditionally, a diarization system is a combination of multiple, independent sub-modules, which are optimized individually. Recently, end-to-end deep learning methods are becoming more popular. The metric for speaker diarization is diarization error rate (DER), which is the sum of false alarm, missed detection and confusion between speaker labels.
In this article, we will introduce our upcoming speaker diarization system first, then give an overview of the latest research in end-to-end speaker diarization.
Our Method
Our product uses a traditional diarization pipeline, which consists of several components: speech turn segmentation, speaker embedding extraction, and clustering. We utilize pyannote.audio [2], an open-source toolkit for speaker diarization, to train most of our models.
1. Speech Turn Segmentation
The first step of our diarization system is to partition the audio recordings into possible speaker turn segments. A voice activity detection model is used to detect speech regions, while removing non-speech parts. Speaker change detection model is used to detect speaker change points in the audio. Each of these models are trained to optimize a sequence labeling task: With sequence of audio features as input, output a sequence of labels.
For both models, there are some tunable hyperparameters which determine how sensitive the models are on segmenting the audio. For the speaker change detection model, only audio frames with detection score higher than the threshold “alpha” are marked as speaker change points. We notice that it is generally more beneficial to segment more aggressively (i.e. split the whole audio into more segments) in the speech turn segmentation stage, so as to make sure most segments only contain one speaker. After the clustering stage, we can merge segments assigned to the same speaker for better Speech Recognition performance in following stages.
2. Speaker Embedding Extraction
After performing speech turn segmentation, in order to facilitate clustering of speaker segments in the clustering module, a speaker embedding model is used to obtain a compact, fine-grained representation for each segment.
The model we choose is SincTDNN which is basically a x-vector architecture where filters are learned instead of being handcrafted. Additive angular margin loss is applied to train the model.
We utilize CNCELEB [3], an open source large-scale chinese speaker recognition dataset, to fine tune the model pretrained on voxceleb. CNCELEB is a challenging, multi-domain dataset consisting of 3,000 speakers in 11 different genres. By using such a diverse dataset, we expect our model to be stable enough when facing various real life scenarios. We also notice that only very few epoch is needed to fine tune the model, and that speaker embedding with lower EER may not always imply lower diarization error rate.
3. Clustering
Traditional cluster methods can be used to cluster the speaker embedding, identifying which speaker each segment belongs to. In our system, we leverage affinity propagation for short audio, and KMeans for long audio. Since we do not know how many speakers are in the recording, affinity propagation has relatively better performance than KMeans as it can determine the number of clusters directly. While for KMeans, we estimate the best number of clusters by finding the elbow of derivatives in MSCD. However, we resort to KMeans instead of affinity propagation for longer audio files since affinity propagation tends to be slower in this situation.
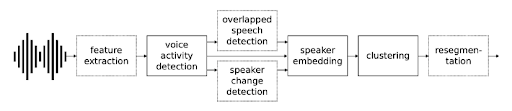
Combining all components
With all the aforementioned components trained, we can combine them into a complete pipeline for diarization. Several hyperparameters are optimized jointly to minimize diarization error rate on a certain dataset.
Compared to our previous system, the current system obtains around 30% DER relative improvement on our internal dataset flow-inc, which consists of a few thousands news recordings. Most improvements stem from improved speaker embedding and clustering method, which improved from 15% to 8% DER for oracle speech turn segmentation setting.
In our production system, we also allow some extra customization for our users. For instance, if the user provides the number of speakers in the recording, we can use KMeans to recluster according to the number of speakers. Also, if the user provides or corrects some speaker labels of the utterances, this extra information is involved when updating the cluster centers. Re-cluster will progress with partial initialization based on updated centers, resulting in more accurate predictions.
Finally, the output of speaker diarization can be further fed to the input of an ASR system, and the final output is the transcript for each speaker turn. It is not very certain if diarization can help improve ASR performance; however, recent work has shown that ASR with diarization can obtain comparable WER as state-of-the-art ASR system, but with extra speaker label information.
What’s Next?
While most systems in production still follow the traditional pipeline of speech turn segmentation + clustering, End-to-end diarization systems are receiving more and more attention. As traditional pipeline assumes single-speaker per block while extracting speaker embedding, it can by no means handle the problem of overlapping speech. End-to-end diarization systems receive frame-level speech features as input, and directly output frame-level speaker activity for each speaker, thus can handle overlapping speech in an easy manner. Also, end-to-end systems minimize diarization error directly, getting rid of the need to tune hyper-parameters of several components. Today, end-to-end systems are able to perform on par with, or even better than traditional pipeline systems in many datasets.
However, end-to-end systems still have several drawbacks. Firstly, these systems cannot easily handle an arbitrary number of speakers. The originally proposed EEND [4] can only deal with a fixed number. Several follow-up works attempt to address this problem, but their systems still struggle to generalize to real world settings, where there may be more than 3 speakers.
Secondly, while end-to-end systems are optimized directly for diarization error rate, they may easily overfit to the training dataset, for instance the number of speakers, speaker characteristics, as well as background conditions. In contrast, traditional clustering-based approaches are shown to be more robust across datasets. Lastly, most end-to-end diarization systems use transformer or conformer as their core architecture. Self-attention mechanism in transformer has quadratic complexity, which hinders the model’s capability to process long utterances or meetings.
Recently, hybrid systems integrating both an end-to-end neural network and clustering are proposed [5][6], which try to take the pros of both worlds. Hybrid systems handling overlapping speech with an end-to-end network, and able to handle an arbitrary number of speakers using clustering algorithms. Also, block processing of input audio data [5] significantly shortens the process time of long recordings. This series of research is very promising and deserves more attention.
Finally, many state-of-the-art systems still leverage simulated mixture recordings for training, then fine tune and evaluate on real dataset. This indicates the lack of large-scale real-life dataset for end-to-end training. By introducing more challenging real-life dataset, it is believed that diarization performance can be further improved.
Conclusion
To address the challenging task of speaker diarization, we leverage a system consisting of several neural networks: speech activity detection, speaker change detection, speaker embedding, as well as clustering algorithm. While these components are trained separately, they are optimized jointly by tuning hyper-parameters. For further work, we would like to incorporate an end-to-end segmentation model to handle overlapping speech, as well as making our system more real-time.
Reference
[1] A Review of Speaker Diarization: Recent Advances with Deep Learning https://arxiv.org/abs/2101.09624
[2] pyannote.audio: neural building blocks for speaker diarization https://arxiv.org/abs/1911.01255
[3] CN-Celeb: multi-genre speaker recognition https://arxiv.org/abs/2012.12468
[4] End-to-End Neural Speaker Diarization with Self-attention https://arxiv.org/abs/1909.06247
[5] Advances in integration of end-to-end neural and clustering-based diarization for real conversational speech https://arxiv.org/abs/2105.09040
[6] Towards Neural Diarization for Unlimited Numbers of Speakers Using Global and Local Attractors https://arxiv.org/abs/2107.01545
[7] The yellow brick road of diarization, challenges and other neural paths https://dihardchallenge.github.io/dihard3workshop/slide/The%20yellow%20brick%20road%20of%20diarization,%20challenges%20and%20other%20neural%20paths.pdf

