Label360: An Annotation Interface for Labeling Instance-Aware Semantic Labels on Panoramic Full Images
Deep convolution neural networks have received great success due to the availability of large scale datasets, such as ImageNet[1], PASCAL VOC[2], COCO[3], and Cityscapes[4], but most of these datasets only contain normal-field-of-view (NFOV) images. Although spherical images have been widely used in virtual reality, real estate and autonomous driving, there is still a lack of accurate and efficient spherical image annotation tools to create a large set of labeled spherical images that can help train instance-aware segmentation models. Therefore, we developed an innovative annotation tool Label360v2 (Figure 1) to help annotators label spherical images (Figure 2). fast and precisely. We also introduced
a post-processing algorithm that generates the distortion-free spherical annotation masks on equirectangular image. Label360v2 and annotated aerial 360 dataset are available to the public here. (https://github.com/ailabstw/label360)
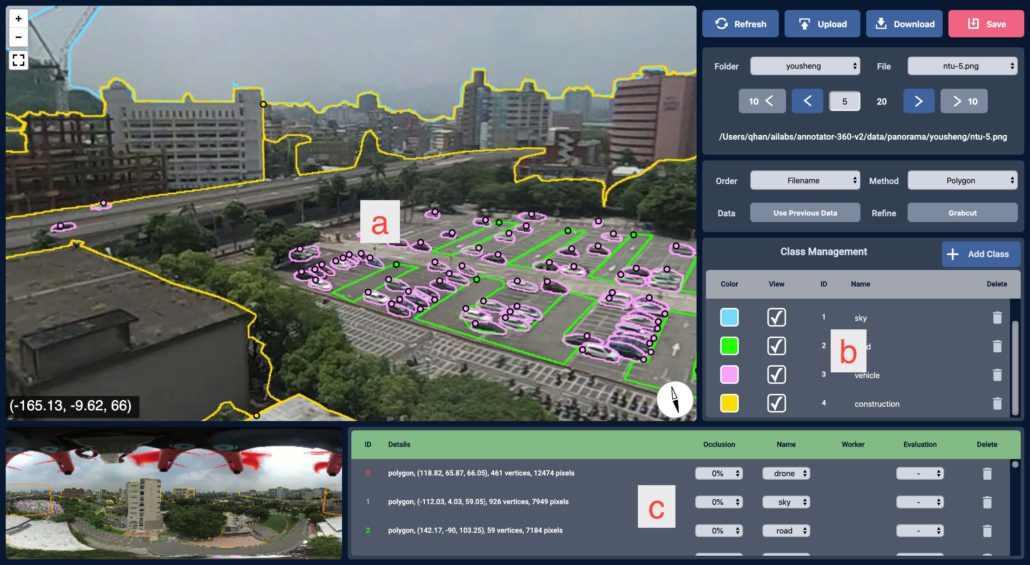
Figure 1

Figure 2
System Design
Annotating a spherical image in equirectangular projection with a standard labeling tool, e.g., LabelMe, directly will have upper and bottom parts of the spherical image suffer from distortion, making the instances difficult to recognize and annotate. Moreover, splitting a spherical image into several NFOV images first before labeling will create instance matching issues if there is an overlapping instance in more than one NFOV image.
To solve these issues, our Label360v2 displays spherical images by rectilinear projection, which eliminates the distortion issue and helps annotators gain a better understanding of the image content. The annotators can also change the viewing direction and the field-of-view arbitrarily during annotation. This helps users annotate instances of any size or at any position.
Besides the features mentioned above, Label360v2 is easy for novices to learn. The annotation process has two main steps: 1) Define class names and assign colors in the class management panel. 2) To annotate a new instance, select an annotation class first and click along the target boundary or an edge in the NFOV viewer to form a polygon. To edit an existing polygon, select it in the data panel or in the NFOV viewer to view all the vertices. A user could add, move, or delete a vertex. To delete an existing polygon, click the trash can button in the data panel.
After the annotation process is completed, our post-processing algorithm generates the spherical annotation masks Fig1. by connecting the vertices using the arcs of the great circle instead of straight lines. It greatly reduces the distortion of the annotation masks, especially when the masks are rendered to an equirectangular image.
Experiments
Two annotators were asked to label 7 classes (Figure 3) on 20 different spherical images using the Label360 tool. We found that they yielded similar results where every class had the mean intersection over union (mIoU) 0.75 (Figure 4). We then asked one annotator to label the same images again using LabelMe[5] instead. Label360v2 took about 83 minutes per image, whereas LabelMe took about 134 minutes (Figure 5) This means the annotation speed of labeling using Label360v2 is around 1.45x annotation speed of LabelMe.
The annotations labeled with LabelMe have more vertices than with Label360v2 because most straight lines in NFOV are distorted into curves in spherical images, and so it requires more vertices to fit the curved boundaries. Moreover, the upper and bottom parts of the panorama suffer from great distortion, which adds to the complexity of the annotation task.
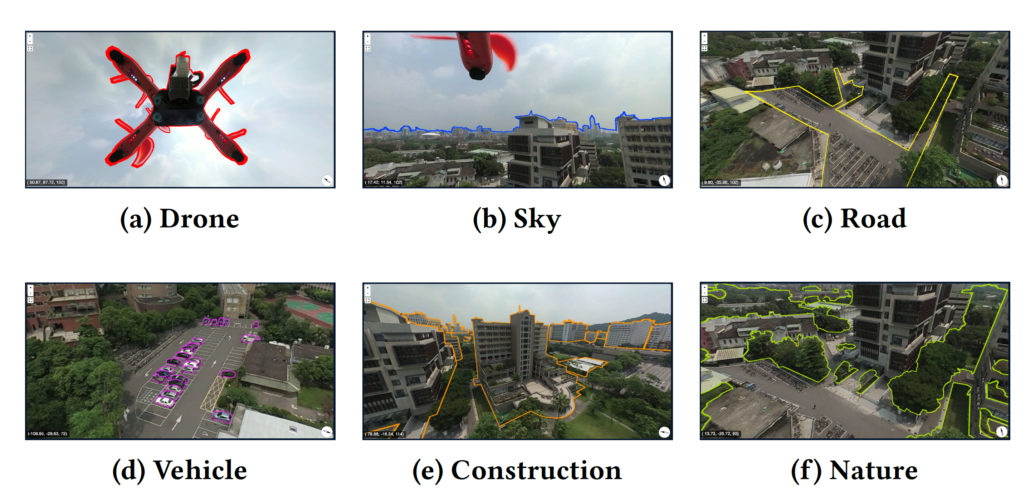
Figure 3
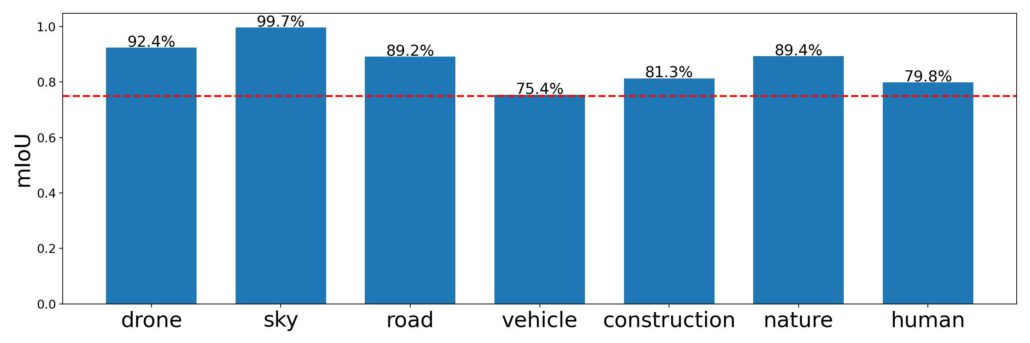
Figure 4
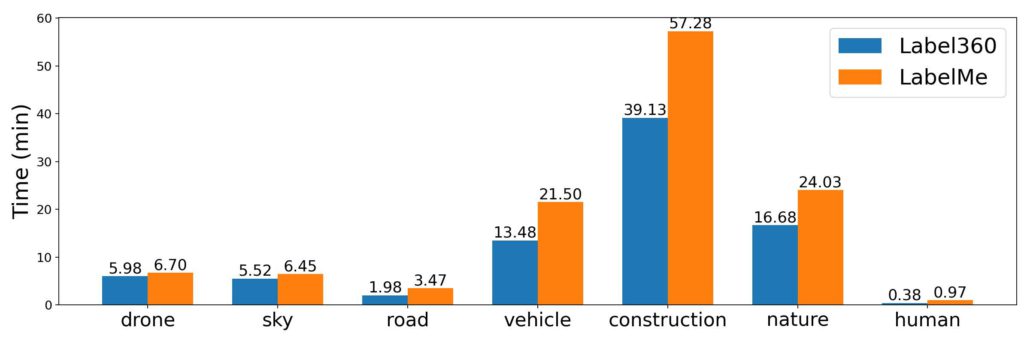
Figure 5
Conclusion
Label360 helps annotators label spherical images in an efficient and precise manner, which reduces a lot of human effort. Also, the post-processing method we provided generates distortion-free pixel-wise labeling masks of spherical images.
Reference

